# Machine Translation
# seq2seq
# Bert
Bert uses exact the same structure as transformers(proposed in attention is all you need), but is pre-trained in a novel way to facilitate bidirectional learning
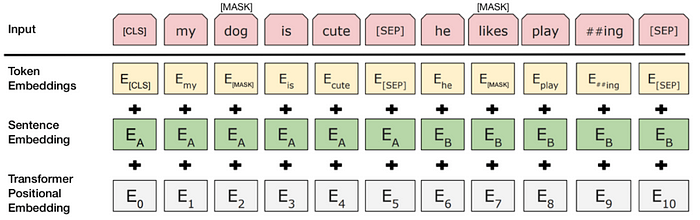
Besides positional embedding and word embedding, bert proposes a token_type embedding(like segment ids) to extend for other tasks
- Transformer1
- multi-head self-attention, relation to other tokens: ([batch x from_seq x heads x x embedding_head_size] * [batch x to_seq x heads x embedding_head_size] => [batch x heads x from_seq x to_seq])
A [PAD]as input,[PAD]score toAis 0, butAto[PAD]is 0.5. Therefore[PAD]attends toAwill not update embedding weights for[PAD], butA attends to[PAD]will update embedding weights for[PAD]`- positional embedding can be fixed with sinusoidal or a learnable variable
- what is sinusoidal
- Transformer2
- Layer Norm
- GeLU
- Pre-training
- Given
[MASK], module is aware that he needs to predict it - 15% of input tokens are masked by 0.8
[MASK], 0.1 random and different token and 0.1 original token. Reason - The output of the
[CLS]token is transformed into a 2×1 shaped vector, using a simple classification layer (learned matrices of weights and biases) - bert is pre-trained on next-sentence classification, so segment ids is needed for bert pre-training
- WordPiece tokenizer, ['hacking'] => ['hack', '##ing']
- embedding table => w
- segment, position => b
- learned position embedding, used by bert
- sinusoidal position, this one is fixed but not used by bert
- segment ids [0, 0, 1] are extend to [seq_len(3), embedding_size] with random weights, all 0' weights are the same and distinct from 1's
- more info
- the embedding process is like a fc layer, if input => one hot encoding (inefficient, thus using embedding lookup)
- only attention mask is needed to avoid [PAD] token affecting weight variables being updated in back-propagation
- Given
- Usage

- Code
- Parameter calculation 1, Parameter calculation 2
# Word embedding
# latent semantic analysis
SVD, 全局特征的矩阵分解方法
# word2vec
局部上下文
center and context words. skip-ngram: use center to predict context with neural networks
- [Reading](https://people.eng.unimelb.edu.au/mbouadjenek/papers/wordembed.pdf
- Negative sampling
- softmax on very large context set is time-consuming
- noise contrastive estimation converts to binary classification
- negative sampling to further simply
# GloVe
既使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征(即滑动窗口)
# Bert embedding
context aware
# Tokenizer
# Byte Pair Encoding
Formed by character n-gram, e.g., ana, app. As in unicode, there are 149k+ characters, hence it requires large number of vocabulary to cover mostly used n-grams. And it is very common to see [UNKNOWN] in model's input.
Details in huggingface tokenizer summary
# Byte Level Encoding
A variation of BPE. Use Byte as base unit to form n-gram. Only 256 possible choices for base unit, so it covers mostly used n-grams by only 50k+. 聚沙成塔:关于tokenization(词元化)的解疑释惑
# WordPiece
Given a training corpus and expected vocabulary size D, find the optimal vocabulary list with size D which produces minimal number of tokens after tokenization with it.
# Bottom up
Bottom up: described poorly in Japanese and Korean Voice Search. Similar with Byte-Paired Encoding, except that it merge small tokens which increase the likelihood on the training data the most.
In the paper, it is confusing:
they need to "maximize the likelihood" of each pair, by building a new Language Model (LM) each step - they don't say what constitutes a LM
In huggingface, it is interpreted as:
So what does this mean exactly? Referring to the previous example, maximizing the likelihood of the training data is equivalent to finding the symbol pair, whose probability divided by the probabilities of its first symbol followed by its second symbol is the greatest among all symbol pairs. E.g. "u", followed by "g" would have only been merged if the probability of "ug" divided by "u", "g" would have been greater than for any other symbol pair. Intuitively, WordPiece is slightly different to BPE in that it evaluates what it loses by merging two symbols to ensure it’s worth it.
In zhihu, it is interpreted as:
合并比如决策树,在某个节点拆分前,会考虑到拆分前和拆分后的信息增益,比如我们选择了x这个特征进行拆分,那么在拆分前,其信息熵为 , 拆分后为: , 也就是说,拆分前后的信息增益为:, 整合后的结果是: , 也就是说"e"和"s"的合并考虑的是概率上的效果提升,而不是单纯的频次
# Top down
Used by bert. Starting with words and breaking them down into smaller components until they hit the frequency threshold, or can't be broken down further. For Japanese, Chinese and Korean this top-down approach doesn't work since there are no explicit word units to start with.
Details in tensorflow text library
# Evaluation
# Similarity
way 1 sklearn.feature_extraction.text.CountVectorizer: tokenize corpus first, and get a count matrix for prediction and ground truth respectively which can be used to compute the matrix similarity score using cosine later
from sklearn.feature_extraction.text import CountVectorizer
import scipy
# supports both char and word
vec = CountVectorizer(ngram_range=(1, 2), analyzer='char')
vec.fit(['sentence 1', 'sentence 2'])
m1 = vec.transform(prediction).todense()
m2 = vec.transform(truth).todense()
def score_calc(v1, v2):
score = scipy.spatial.distance.cosine(v1, v2)
score = 0 if pd.isna(score) else 1 - score
return score
tmp_df = pd.concat([m1, m2], axis=1)
scores = tmp_df.apply(lambda x: score_calc(x[0], x[1]), axis=1)
way 2 Levenshtein distance (number of additions, substitutions, etc.)
from fuzzywuzzy import fuzz
Str1 = "Apple Inc."
Str2 = "apple Inc"
Ratio = fuzz.ratio(Str1.lower(),Str2.lower())
references